Introduction to SQL¶
What is SQL¶
SQL == Structured Query Language
It was first invented in the early 1970s at IBM.
Based on Relational Algebra and Tuple Relational Calculus, it was used to get at data stored in their System-R database management system.
The idea was picked up by Relational Software (now Oracle) in the late 1970s, and let to their release of Oracle V2, the first commercial Relational Database, in 1979.
IBM followed with System/38, SQL/DS and DB2 between 1979 and 1983.
source: http://en.wikipedia.org/wiki/SQL
SQL, and Relational Database Management Systems (RDBMS) have been the de-facto standard for data persistence for 30+ years. Currently, there are more than 100 RDBMS available, both proprietary and open-source. Most, if not all, include some implementation of SQL as their query language.
source: http://en.wikipedia.org/wiki/List_of_relational_database_management_systems
Big Players in SQL¶
There are a number of RDBMS that you will run into regularly
Commercial / Proprietary
- MS SQL Server
- Oracle
- MySQL Enterprise (Oracle)
Open Source
- PostgreSQL
- MySQL community (also owned by Oracle)
- MariaDB (a community-owned fork of MySQL)
- SQLite
SQL/RDBMS Concepts¶
There are a few important concepts to understand when speaking about databases:
Tables¶
A table consists of rows (also called records) and columns. Each row/record represents a single item. Each column represents a data point within that item. Most tables will have one column which is considered the primary key (but not all). This value will uniquely identify a single row out of all the rows in the table. The primary key of a table will be indexed, which allows the database system to find the row using that value spectacularly quickly. Columns other than the primary key can also be indexed.
Here is an example table which represents people in a system:
| id | username | first_name | last_name |
|---|---|---|---|
| 1 | wont_u_b | Fred | Rogers |
| 4 | neuroman | William | Gibson |
| 5 | race | Roger | Bannon |
| 6 | harrywho | Harry | Houdini |
| 7 | whitequeen | Emma | Frost |
| 8 | shadowcat | Kitty | Pryde |
Relations¶
You can model things using tables like this. Adding columns for all sorts of different data points. But what happens when not all of the items in a table share the same data points? Or what if some of the items need to have more than one value for a particular data point? Leaving columns empty in a row wastes memory and slows down querying. Databases use relations to solve these types of problems.
There are three basic types of relationships:
- Many-to-one relationships:
- Used to represent relationships of ownership or belonging. Like product -> manufacturer or book -> author
- One-to-one relationships:
- Best used to represent aspects of an item which are not core to it. Like user (id, password) -> user_profile (preferences, name, address)
- Many-to-many relationships:
- Used to represent associations or membership. Like users -> groups or items -> orders
Relations: ∞ -> 1¶
Many-to-one relationships are modelled using Foreign Keys. The many table has a column, the value of which is the primary key of the row from the one table.
Consider the relationship of books to author:
People:
| id | username | first_name | last_name |
|---|---|---|---|
| 4 | neuroman | William | Gibson |
| 6 | harrywho | Harry | Houdini |
Books:
| id | title | author |
|---|---|---|
| 1 | Miracle Mongers and their Methods | 6 |
| 2 | The Right Way to Do Wrong | 6 |
| 3 | Pattern Recognition | 4 |
By matching the value in the author column of the books table to the value in the id column of the authors table, you can see that Harry Houdini has two books belonging to him, while William Gibson only has one.
Relations: 1 -> 1¶
One-to-one relationships are really just a special case of Many-to-one, and are also modelled with Foreign Keys. In this case, the column on the related table which holds the primary key of the target table has an additional unique constraint This means that only one row in the related table may contain a given target primary id. The classic purpose is for data that doesn’t need to be accessed often, and is unique per record.
Consider this example of birth records:
People:
| id | username | first_name | last_name |
|---|---|---|---|
| 1 | wont_u_b | Fred | Rogers |
| 4 | neuroman | William | Gibson |
| 5 | race | Roger | Bannon |
Birth Records:
| id | person | date | place |
|---|---|---|---|
| 1 | 1 | March 20, 1928 | Latrobe, PA |
| 2 | 4 | March 17, 1948 | Conway, SC |
| 3 | 5 | April 1, 1954 | Wilmette, IL |
Each person is associated with one and only one birth record.
It wouldn’t make sense to have it otherwise.
And with a proper database like postgresql, adding a unique constraint to the people column of the birth records table means that if you try to create a second record with the same value as one already present, an error will be raised.
This concept is called data integrity, and some databases are better at preserving it than others.
Relations: ∞ -> ∞¶
Many-to-many relations are a bit trickier to model. No column in a database can contain more than one value, so there’s no way to define a foreign key-like construct that would work. Instead, this relationship is modelled using a third table, called a join table, which has two foreign key fields, one for each side of the relation.
Often such a join table will have only three columns, the primary key for a given row, and the two foreign keys that form the bridge between the joined entities. But you can also add other columns to model data describing the qualities of the relationship itself.
Consider this set of tables, modelling the membership of people in groups:
People:
| id | username | first_name | last_name |
|---|---|---|---|
| 7 | whitequeen | Emma | Frost |
| 8 | shadowcat | Kitty | Pryde |
Groups:
| id | name |
|---|---|
| 1 | Hellfire Club |
| 2 | X-Men |
Membership:
| id | person | group | active |
|---|---|---|---|
| 1 | 7 | 1 | False |
| 2 | 7 | 2 | True |
| 3 | 8 | 2 | True |
The membership table forms the connection between a person and the groups they belong to.
By adding an active column to that table, it is possible to model the quality of a person’s membership in a group being active or inactive.
You might extend such a model, adding start and end dates or the names of positions held in a group by the person.
SQL Syntax¶
SQL is a formal language with a limited syntax. The syntax can be broken into a set of constructs. If you are familiar with these constructs, you can read an SQL statement and understand its purpose. And you can write statements of your own to interact with the database.
- Statements are discreet units that perform some action, like inserting records or querying
- Clauses are sub-units of statements which indicate some action or condition
- Expressions are elements that produce values, either unitary or as tables themselves
- Predicates are conditionals which produce some boolean or three-valued truth value
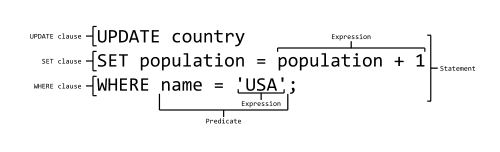
image: CC-BY-SA by Ferdna http://en.wikipedia.org/wiki/File:SQL_ANATOMY_wiki.svg
{kind=link}
Subsets¶
All SQL statements can be thought of as belonging to one of three subsets:
- Data Definition:
Statements in this subset concern the structure of the database itself
CREATE TABLE "jos_groups" ( "group_id" CHARACTER VARYING(32) NOT NULL, "name" CHARACTER VARYING(255) NOT NULL, "description" TEXT NOT NULL )
Common operations in this layer include
CREATE TABLE,ALTER TABLE,DROP TABLEand so on.- Data Manipulation:
Statements in this subset concern the altering of data within the database
INSERT INTO people (username, first_name, lastname) VALUES ('wont_u_b', 'Fred', 'Rogers') UPDATE people SET first_name='Bill' WHERE id=4; DELETE FROM people WHERE id=6;
Common operations in this layer include
INSERT,UPDATEandDELETE.- Data Query:
Statements in this subset concern the retrieval of data from within the database:
SELECT user_id, COUNT(*) c FROM (SELECT setting_value AS interests, user_id FROM user_settings WHERE setting_name = 'interests') raw_uid GROUP BY user_id HAVING c > 1;
SELECTis the only operation in this layer.
If you wish to learn more about SQL, you could run through this tutorial or any of a large number of others online. But for now, that will be sufficient for your current purposes.
SQL Persistence in Python¶
In Python, PEP 249 describes a common API for interacting with a database called DB-API 2.
The goal was to
achieve a consistency leading to more easily understood modules, code that is generally more portable across databases, and a broader reach of database connectivity from Python
source: http://www.python.org/dev/peps/pep-0248/
It is important to remember that PEP 249 is only a specification. There is no code or package for DB-API 2 on it’s own.
Since 2.5, the Python Standard Library has provided a reference implementation of the api (py3) based on SQLite3.
Before Python 2.5, this package was available as pysqlite.
To use the DB API with any database other than SQLite3, you must have an underlying API package available. Implementations are available for:
- PostgreSQL (psycopg2, txpostgres, ...)
- MySQL (mysql-python, PyMySQL, ...)
- MS SQL Server (adodbapi, pymssql, mxODBC, pyodbc, ...)
- Oracle (cx_Oracle, mxODBC, pyodbc, ...)
- and many more...
source: http://wiki.python.org/moin/DatabaseInterfaces
Most db api packages can be installed using typical Pythonic methods:
$ pip install psycopg2
$ pip install mysql-python
...
However, most api packages will require that the development headers for the underlying database system be available. Without these, the C symbols required for communication with the db are not present and the wrapper cannot work.
Preprarations for Class¶
In class we will be exploring interacting with a database using raw SQL and a more advanced concept called an ORM or Object-Relational Mapper.
Install PostgreSQL¶
The first step in working with PostgreSQL (or any other RDBMS) is to install the database software.
If you are using OS X, please follow these steps to install PostgreSQL via homebrew.
If you are using ubuntu linux, please follow these instructions. Stop after the section Create a New Role (make a role with the same name as your login user).
If you are using windows, follow the steps here.
Create a Database¶
The second step is to create a database. Installing the PostgreSQL Software initializes the database system, but does not create a database for you to use. You must do this manually.
There are two ways to accomplish this. For most, the best way is to use the createdb shell command:
$ createdb psycotest
If you are using windows you’ll instead need to connect to the database with psql and use the CREATE DATABASE command from there:
cewing=# CREATE DATABASE psycotest
You can read more about creating a database in the PostgreSQL documentation.
This will create a database called psycotest owned by the role within PostgreSQL with the same name as your current OS user. In class we’ll use this database to test out interacting via Python.
Check to be sure that the database is now present, using the psql command:
heffalump:psycopg2 cewing$ psql
psql (9.3.2)
Type "help" for help.
Once connected you can list the databases in your server instance:
cewing=# \d
No relations found.
cewing=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-------------+--------+----------+-------------+-------------+-------------------
cewing | cewing | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
dvdrental | cewing | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
postgres | cewing | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
psycotest | cewing | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
template0 | cewing | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/cewing +
| | | | | cewing=CTc/cewing
template1 | cewing | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/cewing +
| | | | | cewing=CTc/cewing
(7 rows)
You won’t have a list so long, but you should see psycotest listed.
The psql command opens an interactive shell in PostgreSQL (similar to the Python interpreter).
While you are in this shell you are working directly in the database system.
Warning
If you do not designate a specific database with the -d flag when connecting, you will be connected to a database with the same name as the user who is connecting.
If no such database exists, then psql will fail to start.
Once the psql shell starts, you can simply type SQL commands directly into it. Your commands will be executed in the database to which you are connected. The psql shell provides a number of other, special commands. In the session above we can see some of them:
\llists all the databases present in the server.\callows you to change the database you are interacting with. Give it a database name as an argument.\ddescribes the tables in a database. It can also take the name of one table as an argument, in which case it describes the columns in that table.\qexits from the terminal and returns you to your normal shell session.
There is much more to learn about psql but that will get you going for now.
Create Tables¶
A database is nothing without tables, so we need to create some.
The set of SQL commands that create and modify tables within a database is called the Data Definition Layer.
We’ll create a simple two-table database to play with in class.
At your psql command prompt, change the database you are interacting with to the psycotest one you created above:
cewing=# \c psycotest
You are now connected to database "psycotest" as user "cewing".
psycotest=#
Next, type the following SQL commands at the prompt. You can press enter to get newlines that match, psql will not evaluate what you have typed until you use a semi-colon to terminate the statement:
psycotest=# CREATE TABLE author(
psycotest(# authorid serial PRIMARY KEY,
psycotest(# name varchar (255) NOT NULL
psycotest(# );
CREATE TABLE
psycotest=# CREATE TABLE book(
psycotest(# bookid serial PRIMARY KEY,
psycotest(# title varchar (255) NOT NULL,
psycotest(# authorid INTEGER REFERENCES author ON UPDATE NO ACTION ON DELETE NO ACTION
psycotest(# );
CREATE TABLE
psycotest=#
Now, when you use the \d command to show the tables in this database, you should see the two you just created:
psycotest=# \d
List of relations
Schema | Name | Type | Owner
--------+---------------------+----------+--------
public | author | table | cewing
public | author_authorid_seq | sequence | cewing
public | book | table | cewing
public | book_bookid_seq | sequence | cewing
(4 rows)
psycotest=#
Notice that there are actually 4 relations. The two tables you created and two sequences with names that match our primary keys. These relations are how PostgreSQL generates sequential integers to serve as primary keys. When a new row is created in one of the tables, the next value in the sequence is used as the value of the primary key for that row.
Each table then has a set of columns.
These columns define the types of data that the table is concerned with.
In both tables we have a PRIMARY KEY column.
This column is used to identify rows in the database and must contain unique values.
The data type serial helps to ensure this as it automatically assigns integer values starting with 1 and counting upwards.
In both tables we also have a column containing VARCHAR data.
This type requires that we designate the maximum size of the data that will be held here.
Each of these columns is marked as NOT NULL, meaning that a value is required.
Finally, in the book table there is an INTEGER column which REFERENCES a column in the other table.
This creates a Foreign Key relationship between the two tables.
Relationships such as this are central to SQL databases and are the reason such systems are called RDBMSs, or Relational Database Management Systems.
Using the \d command with a table name argument, you can see the description of each of the tables you’ve created:
psycotest=# \d author
Table "public.author"
Column | Type | Modifiers
----------+------------------------+-----------------------------------------------------------
authorid | integer | not null default nextval('author_authorid_seq'::regclass)
name | character varying(255) | not null
Indexes:
"author_pkey" PRIMARY KEY, btree (authorid)
Referenced by:
TABLE "book" CONSTRAINT "book_authorid_fkey" FOREIGN KEY (authorid) REFERENCES author(authorid)
psycotest=# \d book
Table "public.book"
Column | Type | Modifiers
----------+------------------------+-------------------------------------------------------
bookid | integer | not null default nextval('book_bookid_seq'::regclass)
title | character varying(255) | not null
authorid | integer |
Indexes:
"book_pkey" PRIMARY KEY, btree (bookid)
Foreign-key constraints:
"book_authorid_fkey" FOREIGN KEY (authorid) REFERENCES author(authorid)
Go ahead and quit the psql shell, using the \q command:
psycotest=# \q
Working Environment¶
In class you’ll want to have a nice test environment available to work in. Your final task is to set that up.
Create a folder to work in:
Banks:~ cewing$ mkdir psycopg2
Then create and activate a virtualenv in that directory:
Banks:~ cewing$ cd psycopg2
Banks:~ cewing$ virtualenv ./
New python executable in psycopg2/bin/python
...
Banks:psycopg2 cewing$ source bin/activate
[psycopg2]
Banks:psycopg2 cewing$
Note
If you run into errors building psycopg2 on Ubuntu/Debian linux that say Error: pg_config executable not found, you’ll want to check out this question on stack overflow.
Now that you’ve got the environment set up, and a project folder to work in, go ahead and install the software you’ll need for class:
Banks:psycopg cewing$ pip install psycopg2
Collecting psycopg2
...
Running setup.py install for psycopg2
Successfully installed psycopg2-2.6.1
[psycopg]
Banks:psycopg cewing$ pip install sqlalchemy
Collecting sqlalchemy
...
Running setup.py install for sqlalchemy
Successfully installed sqlalchemy-1.0.12
[psycopg]
Banks:psycopg cewing$
Once that’s successfully done, you are ready for class.